

Evolving a communications intelligence
Artificial intelligence (AI) has long been used to benefit businesses and help them achieve a competitive advantage. From alleviating teams from having to complete repetitive tasks to providing in-depth data visualization that assists in data-driven decision making, AI can provide incredibly meaningful insights.
Whispir is no stranger to AI, having integrated it into our own business intelligence software. Every day, Whispir sends out millions of communications, including email, SMS, and WhatsApp messages.
In this article, we illustrate how we use automated text analysis to classify and group Whispir messages based on the content of the message, and how a business intelligence tool such as ours can benefit you.
The concept of using artificial intelligence (AI) to classify text and provide data analysis has been around for a fair amount of time (think of automated filtering of spam in Gmail). This is a classic data science problem.
Our team liaised with various sources within the company (e.g. our solutions architects) and as a first step came up with 12 message types based on the types of messages that business users are sending within Australia. These include messages relating to business processes like (but not limited to) medical appointment reminders, bushfire warnings, shift time updates, and marketing messages.
This gave us a strong foundation for understanding the specific needs our software tools needed to meet, by delving into the types of messages that we send out and providing helpful information that can be used to make better decisions about the design of future intelligent product features.
This project was a proof-of-concept as part of our vision in evolving our platform into a genuine communications intelligence. Therefore, this article will focus highly on the workflow and intelligent automation tools used to generate and train our message type predictor model and classify our data.
Finding a common language
Machine learning is a branch of AI that focuses on creating algorithms that enable computers to learn tasks based on examples and/or improve over time without being programmed to do so.
Computers are great at working with structured data such as numbers, spreadsheets, and database tables. But our messages fall into the category of unstructured data - that is, they are conveyed using words and human languages, not in numbers such as binary code.
So, we need to break our messages down into a format that our computer (aka “machine”) can read. And this is where things get interesting.
To do this, we use a branch of machine learning known as Natural Language Processing or “NLP”.
In particular, we use a type of machine learning known as supervised learning, where the problem has predefined training data. After data collection, this data is labeled by humans and coded into the machine learning model so that it can learn from these predefined labels in its native ‘language’. After being fed several examples, the model learns to differentiate types of messages and starts making associations as well as its own predictions.
To obtain good levels of accuracy, we need to train our model on a large number of examples that are representative of the everyday subset of the messages that we send out.
Using data analytics for training
The first step in training a classifier model is uploading a set of examples and tagging them manually.
To ensure the security and privacy of all contacts, any personally identifiable information (PII) is scrubbed out of the messages using Amazon’s Comprehend tool.
Using a computer-generated, randomised sample of 5,000 de-identified messages taken from July to December 2020, a team of Whispir staff manually labeled the messages to ensure confidentiality.
The team came up with 12 distinct categories based on the content of these messages that largely reflect our suite of use-cases within the Australian market (https://www.whispir.com.au/industries). Some examples of common use-cases at Whispir are:
Booking confirmations
Appointment reminders
Delivery tracking
Marketing campaigns
Customer support
Emergency alerts
Two-factor authentication
Employer support like rostering
Transport alerts
The Tools
First, we need to be able to access our data that is stored securely within Amazon Web Services (AWS) data warehouse - known as the simple storage solution (S3). To do this we used boto3.
Second, we clean, filter, and create a simplified version of our text data using SpaCy.
Third, we vectorize the text and save the embeddings for future use using Scikit-Learn.
Next, we investigate the type of model to use using Scikit-Learn.
Finally, we save our model for inference using pickle.
The workflow in detail
Download dataset from S3
We needed to access our data stored within S3 through AWS for data security and privacy reasons. Boto3 is the name of the Python software development kit (SDK) for AWS. It makes things much easier to work with.
First, you need an AWS account and to set up access credentials. You can follow the steps here to read more about that.
Clean and tokenize the text using SpaCy
SpaCy is an open-source natural language processing library for Python.
It is designed particularly for production use, and it can help us to build applications that process massive volumes of text efficiently. We wrote our own custom tokenizer function using SpaCy and applied it to our messages.
Whispir lexicon: Tokenization
In Natural Language Processing (NLP), tokenization is the process of converting a sequence of characters, words, or subwords into a sequence of smaller units called tokens. This can be breaking a paragraph into sentences, sentences into words, or words into characters.
In short, the text was tokenized, lowercased and lemmatised. It had punctuation, numbers and stop words removed. The contractions were also expanded out. The output looks something like this:

Whispir lexicon: Lemmatised
Lemmatization can be thought of as word normalisation, it’s a way to try to reduce a given word to its meaningful base or dictionary form, known as a lemma. SpaCy is clever in that it will convert a word to lowercase and change past tense to present tense. It then determines the part-of-speech tag by default and assigns the corresponding lemma. For example, “runs”, “running”, “ran” will all be converted to the lemma “run”.
Turning our text into numbers
We needed to create features from the text. To do this, we needed to turn the words into numbers because machines read numbers like we read our native language characters on a page. The features are created from processed text, not raw text.
There are a few ways to turn words into numbers.
We chose each word or “term” in our messages to calculate a measure called Term Frequency - Inverse Document Frequency (TF-IDF).
Whispir lexicon: TF-IDF
TF-IDF is a measure of the originality of a word by comparing the number of times a word appears in a document with the number of documents the word appears in. We used sklearn.feature_extraction.text.TfidfVectorizer to calculate a tf-idf vector for each of our messages.
For example:

After having this vector of representations of the text we can train supervised classifiers to predict the message type of unseen messages.
Model Selection
We were now ready to experiment with different machine learning models, and evaluate their
accuracy and find the source of any potential issues.
Models for investigation:
Logistic Regression
(Multinomial) Naive Bayes
Linear Support Vector Machine
Random Forest
To evaluate the performance of our models, we often look at accuracy, precision, recall, F1 score, and related indicators.

Whispir lexicon: Measuring model performance
When you build a model for a classification problem you almost always want to look at the accuracy of that model as the number of correct predictions from all predictions made. However, accuracy alone is not a great measure to make this decision.
There are a number of other metrics that we look at including: precision, which is the number of correct positive results divided by the number of positive results predicted by the classifier; recall, which is the number of correct positive results divided by the number of all relevant samples; and F1 score, which is the mean of precision and recall.
However, you can’t evaluate the predictive performance of a model with the same data you used for training.
You need to evaluate the model with fresh data that hasn’t been seen by the model before. You can accomplish that by splitting your dataset before you use it.
So, we used the train-test split procedure sklearn.model_selection.train_test_split to estimate the performance of our machine learning models. This subsets our dataset so we can get an unbiased evaluation of our model.
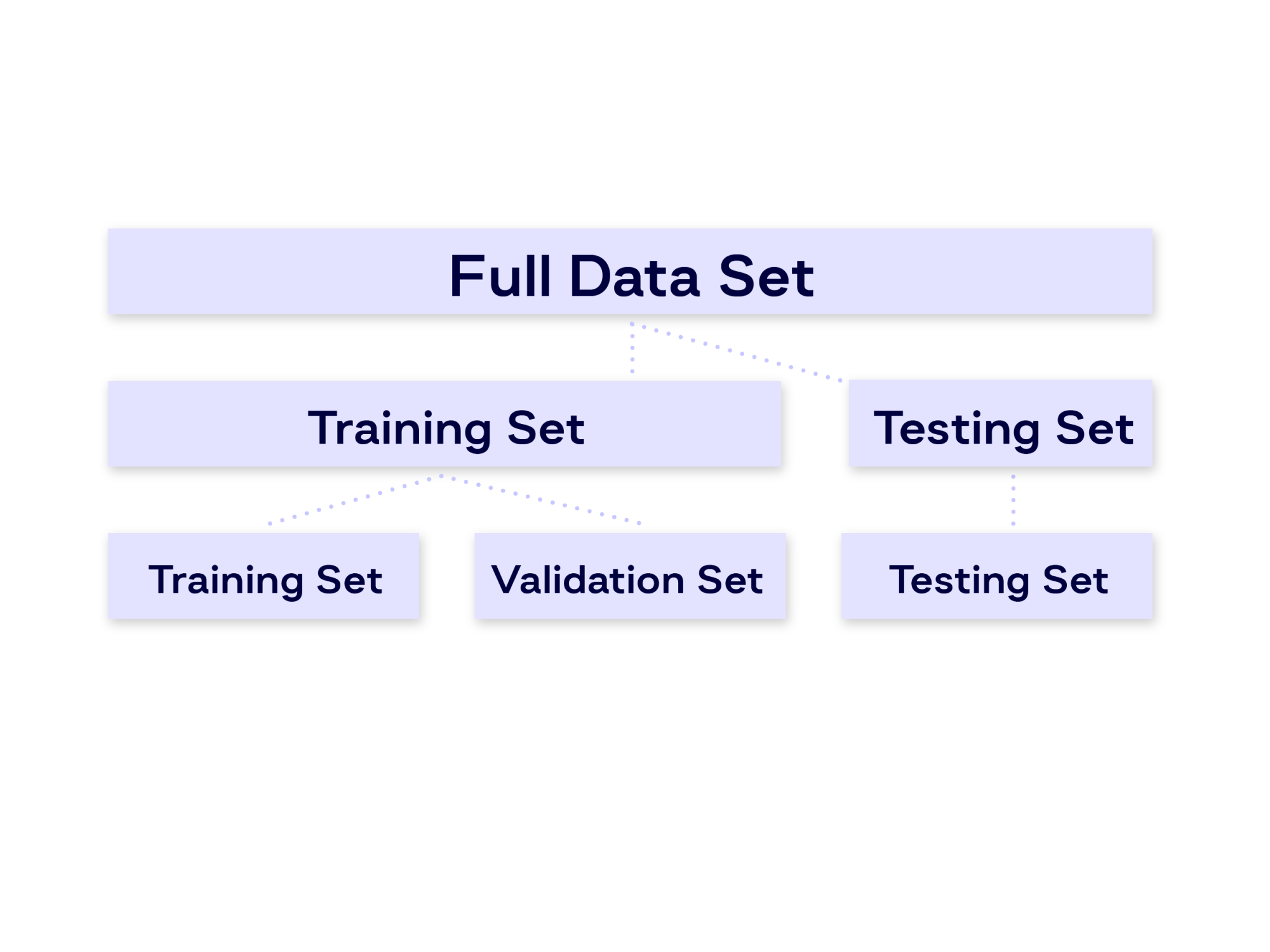
Once our data is split into training, validation, and test datasets, we look at the performance of each model:
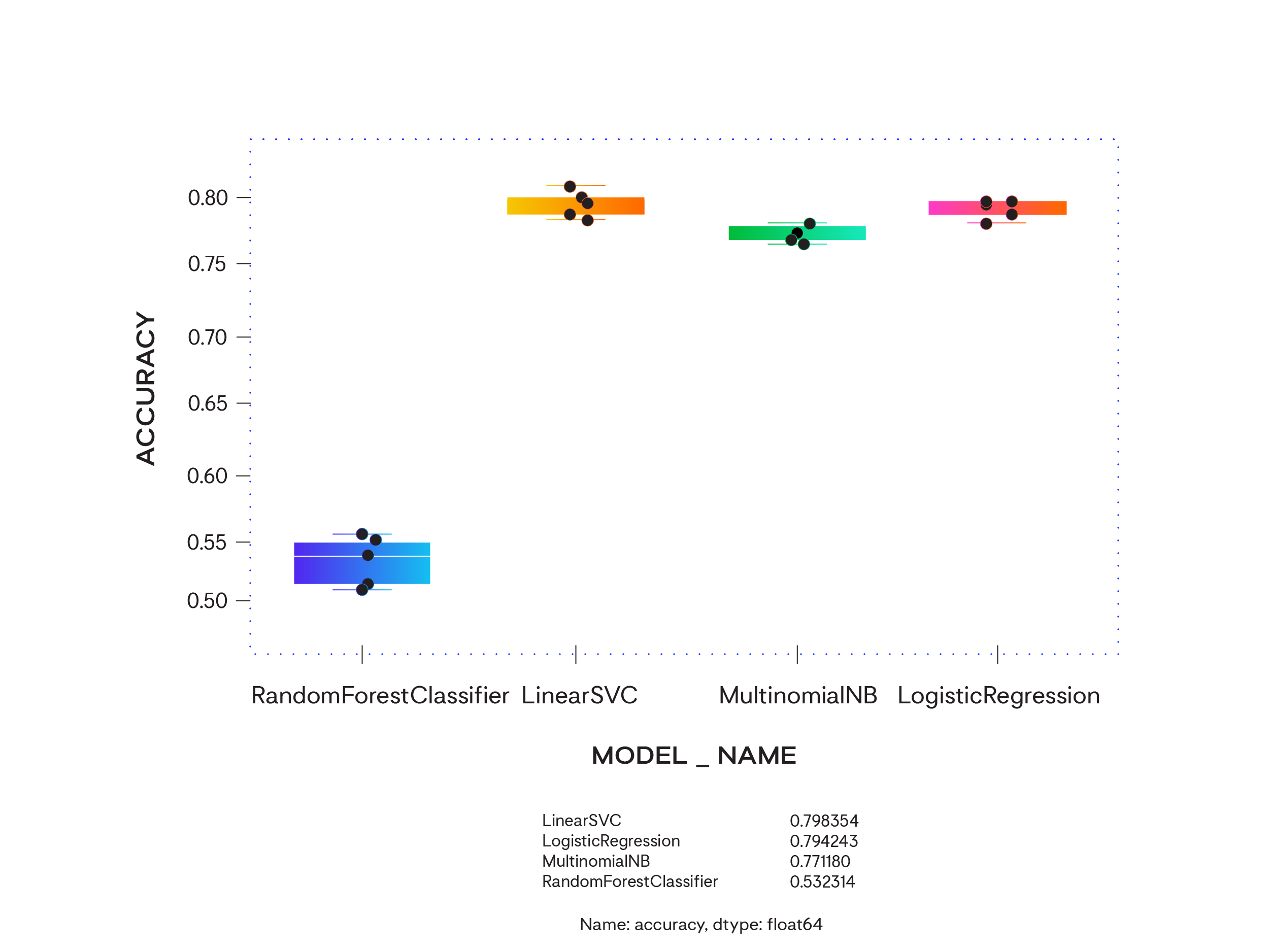
The accuracy of our best-performing model is Linear support vector classifier (SVC) at 79.83%. That’s the fraction of predictions our model got right.
Whispir lexicon: Linear SVC
A linear SVC (Support Vector Classifier) constructs a “best fit” hyper-plane or a set of hyperplanes that can then be used to divide or categorise your data. Once you have the hyperplane, you can then feed some new data to your classifier to see what the "predicted" class is.
Model Evaluation
Our best-performing model was LinearSVC from sklearn.svm import LinearSVC.
We then looked at the confusion matrix, and show the discrepancies between predicted and actual labels:
Whispir lexicon: Confusion matrix
In the field of machine learning and specifically the problem of statistical classification, a confusion matrix, also known as an error matrix, is a specific table layout that allows visualisation of the performance of an algorithm. The matrix compares the actual target values with those predicted by the machine learning model. This gives us a holistic view of how well our classification model is performing and what kinds of errors it is making.
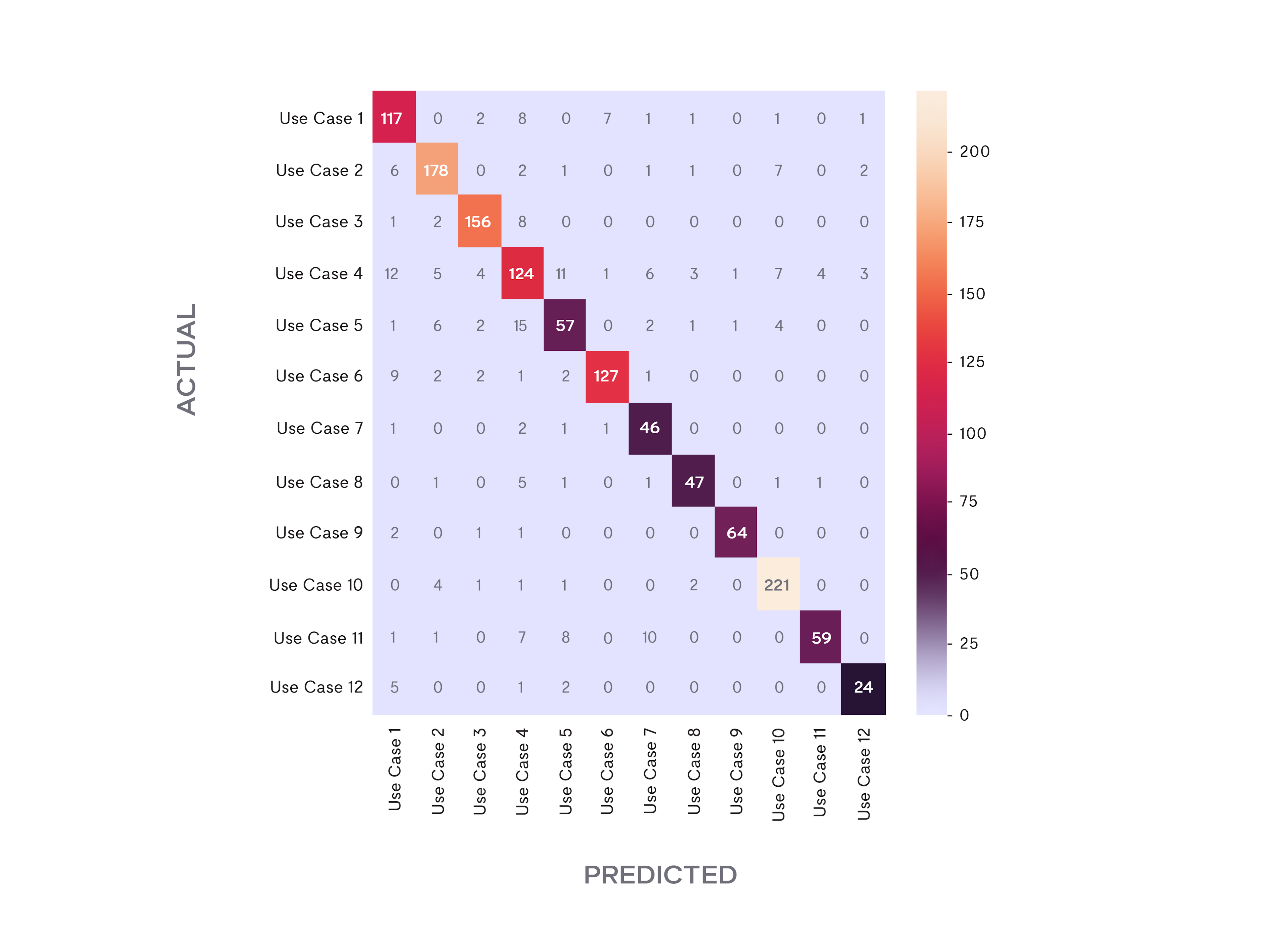
The vast majority of the predictions end up on the diagonal (predicted label = actual label), where we want them to be. However, there are a number of misclassifications, and we need to check those and see what was happening.
Check the misclassifications
Some of the misclassified messages were those that touch on more than one subject. For example, a medical appointment reminder also contains information similar to that of emergency messages (e.g., COVID-19 warnings) due to the medical terminology used within both message types.
This sort of error will always happen. We chose an approach where we decide which class we think is more appropriate. In this case, we examined the top three worst-performing categories and manually re-labeled those messages into categories our team deemed most appropriate. Another approach could be to perform multi-label classification where a message could be classed as both a medical message and an emergency message, but this would involve re-training our model using a slightly different approach.
After cleaning and checking our labels, we then took another look at our performance. It now had 84.37% accuracy.
Given these encouraging results, we decided to go ahead and save this trained classifier model so that it can be tested and potentially used to predict and label our outgoing messages in real-time.
Pickling and saving the model for later use
Pickle is the standard way of serializing objects in Python. You can use the pickle.dump() operation to serialize your machine learning algorithms and save the serialized format to a file. You can then load this saved and trained model at a later date using pickle.load() to calculate the accuracy score and predict outcomes on new unseen (test) data.
At this point, we have trained a model that will be able to classify new messages sent through the Whispir platform into message types. Machine learning model training, however, is only one small step in an end-to-end machine learning project.
There are many steps that still need to be undertaken before this kind of data can be used within Whispir. Machine learning pipelines are iterative as every step is repeated continuously to improve and ensure the accuracy of the model. There are also several other considerations like data governance and data ethics that need to be carefully reviewed in relation to any machine learning project.




